על אותו port ואותו ip?
האם שני לקוחות יכולים להתחבר לאותו שרת webששבב
כן, בהחלטעוקר הרים
אם תרחיבי יותר את השאלה, אני אוכל לענות יותר בהרחבה.
צורת הקישור לשרת הweb לא ברורה ליששבב
כל דף שאפתח בדפדפן זה socket נפרד?לאיזה פןרט פונים ואיזה אי פי?
בקצרה מאודעוקר הרים
באופן כללי ב-web כל בקשה עומדת בפני עצמה - אין "חיבור" לשרת האינטרנט. אמנם נראה לנו שיש חיבור והשרת "זוכר" אותך, אבל זה רק בגלל מידע שהדפדפן מצרף לבקשה (בעיקר עוגיות, אבל יכול להיות גם מידע אחר). ולכן אין הבדל מבחינת השרת אם שתי בקשות הגיעו מאותו טאב, או מטאב אחר. אם בקשה מכילה את אותו מידע, היא תקבל את אותה תשובה.
(החרגה קטנה - לרוב השרת לא ייתיחס לדפדפן, מערכת ההפעלה וה-IP. אם כי, הוא מקבל את הנתונים ויכול להשתמש בהם וכך תתקבל תשובה שונה לאותה בקשה כתלות מאיפה היא נשלחה).
הדפדפן (למעשה, זה ברמת מערכת ההפעלה) יודע לזהות תשובה לבקשה ספציפית ולהחזיר את התשובה ל.
מקום ממנו יצאה הבקשה.
השרת לא יכול להסתמך על IP לזיהוי של משתמש, כי הוא משתנה, ומאחורי IP אחד יכולים להיות עשרות אלפי משתמשים (כך זה בהרבה רשתות של ארגונים, כל התקשורת יוצאת מאותו IP ויש חלוקה פנימית).
כברירת מחדל, כשאתה מקיש כתובת בדפדפן, אם היא http המחשב יפנה לפורט 80, ואם היא https המחשב יפנה לפורט 443. אם יוגדר בשורת הכתובת פורט אחר אז הבשקה תישלח לאותו פורט (לדוגמה http://website:1234 תישלח לשרת website בפורט 1234).
ה-IP שאליו נשלחת הבקשה מתקבל על ידי שרת DNS - שרת כתובות. כשאתה מקליד inn.co.il והמחשב שלך לא יודע מה ה-IP, הוא יפנה לשרת ה-DNS ויקבל ממנו כתובת IP. הכתובת של ערוץ שבע תתורגם לפניה לשרת-195.60.232.74. (ה-www נקרא subdomain, הוא יכול לשמש את השרת לחלוקה פנימית אבל הוא לא חלק מנתוני התקשורת). אם תרצה לראות את ה-ip של הבקשה, תוכל לפתוח את כלי הפיתוח של הדפדפן וללחוץ על בקשה.
תגובהששבב
"
הדפדפן (למעשה, זה ברמת מערכת ההפעלה) יודע לזהות תשובה לבקשה ספציפית ולהחזיר את התשובה ל.
מקום ממנו יצאה הבקשה.
"
המקום ממנו יצאה הבקשה הוא לפי פורט המקור?
ואיזה פורט יהיה במקור?פןרט מוגרל או יחודי לבקשה שפתחתי?
אני לא מספיק מכירעוקר הרים
אבל ממה שבדקתי, הפורט הוא לא ייחודי לבקשה.
יכולות להיות בקשות משני טאבים עם אותו פורט, ושתי בקשות מאותו טאב עם פורט שונה.
זו לוגיקה שהדפדפן מנהל והיא "שקופה" למשתמש/ מתכנת.
אני עקבתי אחרי הבקשות עם procmon.
שתי בקשות עם פורט זהה? אתה בטוח?11111
אלא אם כן במקרה הוגרל אותו פורט פעמיים.
עקבתי באמצעות procmonעוקר הרים
וזה מה שראיתי. זה אכן נראה לי מוזר.
נראה גם שיש חוקיות בפורטים, לרוב הם עוקבים.
לגבי מספרי הפורטיםאלגוריאחרונה
זה קשור לKeep-Alive בHTTP.
ברמת העיקרון בגלל הצורה שבה http עובד אז אחרי כל בקשה + תגובה החיבור יסתיים והסוקט ייסגר.
כשיש Keep-alive הסוקט יישאר עד שיסגרו אותו מסיבה זו או אחרת.
ממה שנראה לי, כנראה זה תלוי בחיבור ובניהול של הסוקט ע"י הדפדפן וגם בHeaderים שנשלחים (למשל Connection: close או Connection: Keep-Alive).
ממליץ קרוא ביתר הרחבה על Keep-Alive אם רוצים לקבל יותר מידע ממה שאני יודע ויכול לספק שמא גם טעיתי.
לגבי מספרי פורטי המקור מהלקוח שמייצר את הבקשה אם הם מוגרלים או לא, מאמין שזה תלוי במימוש של מערכת ההפעלה.
ברמת העיקרון בגלל הצורה שבה http עובד אז אחרי כל בקשה + תגובה החיבור יסתיים והסוקט ייסגר.
כשיש Keep-alive הסוקט יישאר עד שיסגרו אותו מסיבה זו או אחרת.
ממה שנראה לי, כנראה זה תלוי בחיבור ובניהול של הסוקט ע"י הדפדפן וגם בHeaderים שנשלחים (למשל Connection: close או Connection: Keep-Alive).
ממליץ קרוא ביתר הרחבה על Keep-Alive אם רוצים לקבל יותר מידע ממה שאני יודע ויכול לספק שמא גם טעיתי.
לגבי מספרי פורטי המקור מהלקוח שמייצר את הבקשה אם הם מוגרלים או לא, מאמין שזה תלוי במימוש של מערכת ההפעלה.
לא יצא לי לבדוק פרקטיתשמואלג
תאורתית מלמדים שפורט המקור מוגרל לכל 'אפליקציה' (כלומר לכל טאב)
טכנולגית מעקב אישוןמילקה
אני מעונינת לכתוב תכנה שמשתמשת בטכנולוגיה של מעקב אישון
לא בדרך המסובכת והמורכבת שלו אלא רק לבדוק האם הבנ"א נמצא בפריים של המצלמה והאם העיניים שלו פתוחות ולא עצומות
יש למישו מושג מאיפה משיגים/קונים ספריות מוכנות עם כאלו פונקציות או משהו אחר שיכול לקדם אותי בענין?
תודה רבה
באיזה סביבה?איזה_טוב_ה'_
opencvאנונימי (2)
חבילה שקיימת ב-Python ואני חושב שגם ב-c++ (אבל לא בטוח).
אם את כותבת שב-python, הייתי ממליץ לך להתקין אותה עם anconda - אחרת זה סיוט.
ולדעתי, הדרך הפשוטה ביותר היא לשתמש באלגוריתם hough לזיהוי מעגלים (יש דוגמאות מעולות בדוקומנטציה של החבילה באתר שלהם) ולחפש עיגול בתוך עיגול (הקשתית היא עיגול עם רוחב כך שאפשר לחפש את העיגול החיצוני והעיגול הפנימי) בגדלים הרצויים (תלוי במרחק של העדשה מהאובייקט וכו') בשיטה של ניסוי וטעייה.
עוד אפשרות:אנונימי (2)
להוריד מודל מאומן של רשת נוירונים שמזהה פנים - אפשר למצוא כאלה ב-Github, כמו זה למשל:
GitHub - tornadomeet/mxnet-face: Using mxnet for face-related algorithm.
אבל זה דורש הרבה פעמים אפילו יותר עבודה מלכתוב קוד לבד.
וואו תודה אנונימי יקר!!!!מילקה
אני בשלב עשיית פרויקט הגמר
כך שהרבה מהאינפורמציה שנתת אני לא מבינה עד הסוף
אמורה להיות לי מנחה שתעזור לי ותלווה אותי
מה זה בדיוק הקישור שהבאת?
אופציה להורדת ספריה עם פונקציות שיכולות לעזור לי לזהות קיום של אישונים בפריים????
הבנתי נכון?
שוב תודה
בכיףאנונימי (2)
הקישור הראשון שהבאתי הוא קישור לדוקומנטציה של opencv. זו חבילה חינמית שכפי שכתבתי, יש לה ממשק עם python, java, c ו-c++.
זו חבילה של computer vision ויש בה המון פונקציות ושיטות לעיבוד תמונה וראיה ממוחשבת: זיהוי פינות, זיהוי קצוות, נגזרות, מסננים, resize, עקיבה אחרי אובייקטים, optic flow וכו'.
אחת מאותן שיטות היא אלגוריתם שנקרא hough שבאופן כללי, ניתן למצוא באמצעותו בתמונה קוים שמקיימים משוואה מסוימת (כמו משוואת ישר או משוואת מעגל - ככל שהמשוואה מסדר גבוה יותר, החישוב מסובך וארוך יותר, כך שלמיטב ידיעתי אין מימוש לפוקנציה מסדר שלישי ויש רק למשוואת מעגל - סדר שני - אבל זה אמור להספיק למטרה שלך עם כוונון של כמה פרמטרים נומריים שקיימים בקוד של האלגוריתם).
יצא לי להתקין את הספריה רק על מחשב עם מערכת הפעלה לינוקס ועבור python - אבל אם תחפשי בגוגל איך להתקין את החבילה על מערכת הפעלה אחרת עבור שפה אחרת שיש לחבילה ממשק איתה, אני בטוח שתמצאי הסברים מפורטים.
הקישור השני ששמתי הוא עבור מודל מאומן לזיהוי פנים.
למצוא אישונים בתמונה שבה יש פנים, זה די פשוט (שני עיגולים בעלי אותו מרכז בגדלים שונים). לדעת האם יש באדם בתמונה או לא - זה כבר יותר מורכב.
אנשים מאוד מוכשרים אימנו רשתות נוירונים על המון תמונות כך שאפשר לקחת תמונה כלשהי, להעביר אותה במודל והמודל יוכל לסווג את התמונה ל"האם יש פנים בתמונה" או לא. (יש עוד מודלים שאפשר למצוא ברשת).
כלומר, הזרימה צריכה להיות כך שקודם כל הקוד שלך יבדוק האם יש פנים בתמונה ולאחר מכן האם העיניים פתוחות או עצומות (אם הבנתי נכון).
החלק הראשון הוא החלק שצפוי להיות יותר בעייתי.
אוקיימילקה
קראתי מה שכתבת וגם חיפשתי קצת בעצמי
ממה שקראתי באתר של OPENCV יש שם אופציה של זיהוי פרצופים , יכול להיות שזה כזה פשוט?????
תודה רבה (ואגב הבנת נכון לגבי הזרימה)
יכול להיותאנונימי (2)
אני זוכר שגם קראתי משהו על זה (אלגוריתם שמעביר סדרת פילטרים מסוימת על התמונה ומוציא ממנה מידע) - אבל אני באופן אישי לא עשיתי בזה שימוש.
opencv זה עולם שלם שאפשר לנבור בו במשך תקופה ארוכה למדי ולא להכיר את הכל.
אגב, זה גם יכול לעבוד ב-realtime. אפשר לקחת סרטון ולפרוש אותו לפריימים ויש שם גם מימוש של 2 אלגוריתמים שנקראים mog ו-mog2 שיודעים להשוות בין הפריימים הקודם לפריים הנוכחי ולסמן שינויים שקרו ברצף. (אולי זה גם יוכל לעזור).
בהצלחה.
אני לא מבינהמילקה
openCV בבסיס מיועדת לניתוח תמונה סטטית????
הפונקציות של זיהוי הפרצופים לצורך הענין -פועלות על תמונה קיימת או על תמונה שמגיעה כל אלפפית השניה ממהמצלמה?????
תודה רבה
כל האלגוריתמים עובדים על תמונות סטטיות. מה זה וידאו?אנונימי (2)
רצף של תמונות סטטיות.
ישנם אלגוריתמים - כמו MOG שהזכרתי קודם - שמנתחים פריים בודד לפי פריימים קודמים כך שהם יכולים לזהות תנועה - אבל גם זה מבוצע באמצעות אלגוריתמים שפועלים על פריימים בודדים בבסיס האלגוריתם. (ואז האלגוריתם לוקח כל פריים, יוצר לו איזשהו מודל מתמטי שמתאר כל אזור בפריים, משקלל את זה עם המודלים שהתקבלו בפריימים אחרים ובודק אם אזור מסוים בפריים הנוכחי מקיים תנאי כלשהו או לא).
כל ניתוח וידאו פועל על ניתוח רצף של פריימים בודדים.
אין סתירה בין תמונה קיימת לבין תמונה שמתקבל כל אלפית שניה מהמצלמה. תמונה שהתקבלה לפני אלפית שניה מהמצלמה, היא תמונה קיימת.
אפשר ליצור אלגוריתמים על סרטונים בזמן אמת - ויש דוגמאות לזה ב-youtube. חפשי שם opencv ו-mog.
האלגוריתמים שפועלים על אותם סרטונים הם אלגוריתמים שפועלים בבסיס שלהם על תמונות בודדות.
ברור  מילקה
מילקה
אבל מי שכתב את הספריה הזאת תכנן שישתמשו בה בוידאו (רצף של תמונות סטטיות - אם תתעקש)
כלומר - דרך מקובלת להשתמש בספריה הזאת היא על רצף של תמונות סטטיות שמשודר ממצלמת אינטרנט לדוגמא???
אם כן (ואפילו אם זה דורש עבודה רבה ) מצוין , אני לא נרתעת
וסליחה אם אני שואלת שאלות מטומטמות
פשוט חסרת נסיון לחלוטין ואתם עוזרים לי מאדדדדדד
תודה רבה
אחד המרצים שלי היה נוהג לומר:אנונימי (2)אחרונה
"אין שאלות מטומטמות... יש רק אנשים מטומטמים..." (אל תעלבי, אני סתם צוחק וזה לא מכוון אלייך. זה סתם משפט ציני שהוא היה אומר לכל סטודנט שהתחיל את השאלה שלו במשפט: "אולי זו שאלה מטומטמת אבל...". בקיצור, נוסטלגיה...).
מי שכתב את הספריה - או יותר נכון, האנשים הרבים שפיתחו אותה - ניסו ליצור חבילה כמה שיותר שלמה עבור התחום של ראיה ממוחשבת שתכלול גם עיבוד של פריימים בודדים וגם עיבוד של וידאו - כלומר, אלגוריתמים שפועלים על רצפים של פריימים בודדים או קבוצות והשוואה ביניהם.
למשל, אין שום משמעות באלגוריתם MOG עלתמונה בודדת. האלגוריתם הזה מיועד לשימוש על רצף של תמונות.
מצד שני, כדי למצוא מעגלים או קווים ישרים בתמונה - יש להשתמש באלגוריתם שעובד על פריים בודד בכל פעם. (אלגוריתם hough, למשל).
אין "דרך מקובלת" להשתמש בה כמו שאין דרך מקובלת להשתמש בפטיש - אפשר לדפוק איתו מסמר, אפשר לשבור איתו קיר ואפשר להשתמש בו בתור משקולת - זה ארגז כלים מאוד מאוד משוכלל ונח וכל אחד יכול להשתמש בו כראות עיניו.
הדרך הנכונה לדעתי להשתמש בחבילה הזאת (או בכל חבילה אחרת של ראיה ממוחשבת) היא קודם כל להבין איזה אלגוריתמים הם "יקרים" מבחינה חישובית (שזה קריטי באלגוריתמים של real time), אילו אלגוריתמים "זולים", מה בדיוק רוצים לעשות, מהו המפרט והתנאים ההכרחיים שחייבים לעמוד בהם ואיך הכי יעיל לבצע את זה.
למשל, במקרה שלך, אלגוריתם MOG הוא אלגוריתם זול יותר מ-HOUGH ולכן שימוש ב-MOG עדיף כשאפשר וגם אלגוריתם לזיהוי פנים דורש לא מעט חישובים.
מה זה אומר? שאם בוידאו שאת עובדת עליו יש כמה פריימים רצופים שזיהית שאין בו פנים, עדיף להשתמש ב-MOG ולראות האם בפריים שאחריו יש שינוי משמעותי ממה שהופיע בו קודם. (למשל, הגדרת סף של מספר פיקסלים סמוכים שהשתנו).
אם את מזהה שאין שינוי, אז אין טעם לבדוק אם פתאום הופיעו שם פנים, ואפשר לעבור מיד לפריים הבא במהירות ובקלות.
במידה ואת מזהה שינוי במספר גדול מספיק של פיקסלים מחוברים בפריים הנוכחי לעומת אלו שקדמו לו, רק אז את תצטרכי לבדוק האם יש פנים בתמונה (שזה אלגוריתם די יקר) ורק אז יהיה כדאי לך לבדוק האם יש שני מעגלים בקטרים כמעט זהים (עבור שתי העיניים) ובמידה שכן, לבדוק אם יש חוץ מהם עוד שני עיגולים בתוך אותם עיגולים שמצאת קודם. (קסקדה של אלגוריתמים).
אותו דבר בכיוון ההפוך - אם יש לך כמה פריימים שאת כבר יודעת שמופיעות בהם פנים, אז מספיק להריץ MOG כדי לדעת האם משהו השתנה והאם כדאי לעבור לאלגוריתמים יקרים יותר.
כמובן שיש כאן trade-off, כמו כל דבר בעולם ההנדסה.
אם אלגוריתם MOG זיהה שינוי, אז את בכל מקרה צריכה להריץ עכשיו אלגוריתם לזיהוי פנים - כלומר, הרצת MOG "סתם" וזה עלה לך בזמן.
השאלה היא מה יותר חשוב לך והאם את מוכנה לספוג פעם אחת ברצף של תמונות הרצת MOG מיותר בתמורה לזה שזה יחסוך לך הרצה של אלגוריתמים כבדים יותר במקרים אחרים.
בבעיה שאינה של real time, זמן החישוב הממוצע הוא שקובע ולא באמת אכפת לאף אחד כמה זמן עובד כל פריים.
בבעיה של real time, המצב שונה כיוון שיש זמן מקסימלי שמוכנים להשקיע בפריים ספציפי.
לכן, בבעיה של real time, בכל פריים את לא רוצה שיעבור יותר מפרק זמן קצר מאוד שאולי אלגוריתם של זיהוי פנים יעמוד בו אבל MOG ואז אלגוריתם של זיהוי פנים כבר לא יעמוד בו - ואז עדיף לך להעביר כל פריים ישירות במסווג של פנים\אין פנים בתמונה בלי להשתמש כלל ב-MOG.
בקיצור, יש כאן המון שיקולים וכמובן שמהירות חישוב לרוב תבוא על חשבון דיוק וכו'.
יש עוד אפשרות שלא כוללת בכלל opencv - אבל היא דורשת ידע בתחומים של למידת מכונה בדגש על רשתות נוירונים ויכולת לכתוב אותן בצורה יעילה.
אני לא חושב שזה רלבנטי לפרוייקט גמר. (אולי לעבודת מחקר של מאסטר או חלק מעבודת מחקר של דוקטורט...).
Goggle Cloud Vision APIעוקר הרים
עבר עריכה על ידי עוקר הרים בתאריך ב' באב תשע"ז 22:58
Vision API - Image Content Analysis | Google Cloud Platform
לא יצא לי לבדוק, אבל יש שם טכנולוגית זיהוי פנים פשוטה יחסית.
התשובה שמתקבלת כוללת גם הרבה פרטים ונקודות ציון בפנים -
דוגמה פשוטה עבור עם rest api ומספר שפות תכנות -
Detecting Faces | Google Cloud Vision API Documentation | Google Cloud Platform
עד אלף תמונות ביום זה חינם.
תודהמילקה
אבל אני מחפשת מערכת שתעבוד בזמן אמת
אם הבנתי נכון (ולא התעמקתי אז הגיוני מאד שלא) זה טכנולוגיה לזיהוי פנים בתמונה קיימת
לא בתמונה שמשודרת כרגע ממצלמה
נכון?
תלוי מה זה "זמן אמת"עוקר הרים
זה אכן יצריך אותך לשלוח את התמונה ל-google cloud ולא לעבד אותה מקומית.
זה מאוד מהיר, אבל זה כן יכול לקחת כמה מאות מילי שניות לשלוח את התמונה. בתמונות גדולות זה יצריך אותך לכווץ את התמונה.
אגב, אם המצלמה היא סלולארית, יש לגוגל גם API דומה לאנדרואיד.
עכשיו ראיתי שמדובר באלפיות שנייהעוקר הרים
עבר עריכה על ידי עוקר הרים בתאריך ה' באב תשע"ז 00:06
זה פחות רלוונטי מול ה-API של הענן, אבל כן מול ה-API שלהם לאנדרואיד.
יש פה מישהו שהוא בונה אתריםעלה למעלה
ואני יכולה להתייעץ איתו על הצעת מחיר?
שאלהאנונימי (פותח)
אני יודעת כמה שפות. אבל לא מרגישה שזה מביא אותי למשהו. כלומר: אין לי בעיה לכתוב תוכניות. אבל אין לי ניסיון בכתיבת פרוייקטים "רציניים". ואני לא יודעת איך השפות בגדול אמורות להשתלב (כמובן בחלקן)
כאילו משהו תקוע לי...
יש למישהו רעיון לפרוייקט שאני יכולה לעשות מהבית? בשעות הפנאי...
(יודעת סי שארפ. סי פלוס פלוס. אסמבלי.- את אלו מעולה. חוץ מזה לומדת עכשיו פייטון. יודעת קצת html php (סתם כי למדתי את זה בכמה שעות של שיעמום). וקצת ג׳אווה וסי (מבינה.ויכולה לכתוב קטעים פשוטים. אבל לא מעבר)) אין לי בעיה ללמוד עוד נושאים. אני מאוד אוטודידקטית. אבל אני חושבת שמה שאני צריכה עכשיו זה העמקה בידע שיש לי ולא התפרסות נוספת...
כאילו משהו תקוע לי...
יש למישהו רעיון לפרוייקט שאני יכולה לעשות מהבית? בשעות הפנאי...
(יודעת סי שארפ. סי פלוס פלוס. אסמבלי.- את אלו מעולה. חוץ מזה לומדת עכשיו פייטון. יודעת קצת html php (סתם כי למדתי את זה בכמה שעות של שיעמום). וקצת ג׳אווה וסי (מבינה.ויכולה לכתוב קטעים פשוטים. אבל לא מעבר)) אין לי בעיה ללמוד עוד נושאים. אני מאוד אוטודידקטית. אבל אני חושבת שמה שאני צריכה עכשיו זה העמקה בידע שיש לי ולא התפרסות נוספת...
כששאלו בעבראליסף א
זה מה שהצעתי.
את רוצה לשלב כמה שפות?
תנסי לבנות מערכת בית חכם.
קני בקר זול (ארדואינו - מכירה?)
קני לו כמה חיישנים וכמה נורות לד.
(אפשר בארץ - יקר ומהר, ואפשר בחול , זול ולוקח יותר זמן להגיע.)
תני לבקר לדגום חיישנים , ולקבל החלטות איזה נורה הוא מדליק , ומתי.
תעשי ב C# תכנה , שמקבלת מהבקר את נתוני החיישנים בזמן אמת.
ואת מצב נורות הלד.
תציגי את זה על המחשב.
וגם תאפשרי הדלקה וכיבוי דרך המחשב.
(אפשר להמשיך על ידי הוספת תקשורת אלחוטית, להוסיף לארדואינו בלוטוס או וויפי וכו,
אפשר לכתוב אפלקיצייה לטלפון שמתחברת וכו,)
בהצלחה.
איפה לומדים איך לתכנת ארדואינו?מתיישב בנשמה
ועל איזה סוג מומלץ לעבוד בהתחלה?
הפשוט ביותר , והמוכר זה ה UNOאליסף א
קישור:
http://www.arduino.org/products/boards/arduino-uno
השפה היא סוג של C++
יש להם באתר תיעוד.
http://www.arduino.org/learning/getting-started
בגדול - אתה מוריד את תכנת העריכה שלהם -arduini ide
מחבר את הבקר
וצורב תכנה לבקר.
רק UNO? בלי עוד שמות?מתיישב בנשמה
כמה זה עולה בארץ בערך?
בארץאליסף א
יקר , אבל יגיע אליך מהר.
בחו"ל
דוגמא לקישור, יש הרבה חברות שמוכרות אותו
זול, אבל יקח יותר זמן להגיע.
יש המון! ברשתאליסף א
יש ספרים , יש מדריכים וכו,
איך את באנגלית?
מסתבר שיש גם בעברית
מי שמחליט ללמוד ארדואינואליסף א
אני ממליץ שיקנה ערכת חיישנים
עולה 12 - 10 דולר בסין
מקריאה מהירה של המדריך בעבריתאליסף א
נראה שהוא סבבה.
קודם תעבור/י עליו. ואז תראה/י אם את/ה רוצה לקנות ציוד.
בהצלחה
עשית השוואה של ארודיאנו לraspberry pi ודומיו?11111
אלו 2 פלטפורמות שונותאליסף אאחרונה
ב"ה
רספברי פאי זה מחשב לכל דבר.
דרך אגב, באתר בו נמצא המדריך לארדואינו , יש גם מדריך לרספברי פאי.
מהו מספר הקודקודים המינימלי בעץ AVL.?ששבב
מה המקביל ל-ASCIISTR של Oracle ב-SqlServer?מציצה
,usv
אין מקביל ממש עד כמה שאני יודעתשמש צהובה12
את יכולה לעבור בלולאה ולבדוק עם UNICODE() - פונקציה שמחזירה את הערך המספרי של התו הראשון במחרוזת שהועברה (לא רק מטבלת הASCII)
יש למישהו כזאת פונקציה מוכנה?מציצהאחרונה
אני לא מספיק מתמצאת ב-sql...
תודה!
האם יש לי וירוסאנונימי (פותח)
כשהדלקתי היום את המחשב הוא הודיע לי בעברית הודעה שהוא מעדכן את המחשב, ההודעה לא הייתה כמו ההודעות הרגילות של ווינדוס אח"כ המחשב התחיל לעשות לי בעיות , כל הקיצורי דרך בשולחן עבודה זזו ימינה וכשניסיתי להחזיר אותם זה לא נתן לי, בנוסף לכך שניסיתי לפתוח את שורת הפקודה זה מה שהופיע לי:
לא יודעעוקר הרים
רק לגבי שורת הפקודה - ווינדוס שינו את ברירת המחדל של שורת הפקודה מ-cmd ל-powershell.
שני דברים שוניםעוקר הריםאחרונה
cmd הוא שורת פקודה ישנה ופרימיטבית מאוד, מוגבלת ביכולות ובתחביר.
powershell היא שפה שלמה שניתן לעשות באמצעותה כל דבר במחשב (ולא רק).
ה-CMD עדיין קיים וניתן לפתוח אותו בקלות - חיפוש cmd בחיפוש של המחשב.
מאירועי שבוע שעבר... (זה שייך לתחום )conet
)conet
איך אני מתחבר למסד נתונים בתוכנית c# ושולף ממנו נתונים?מתיישב בנשמה
איזה סוג של מסד?איזה_טוב_ה'_
accesמתיישב בנשמהאחרונה
מאוד קשה לעבוד עם מפתח במשרה חלקיתמשה
את לא יכולה לקחת פרוייקטים כי את לא מנוסה מספיק, ואי אפשר לצרף אותך לצוות קיים בגלל שאת לא רוצה משרה מלאה.
תבדקי את האפשרות לעבוד בהתנדבות בפרוייקטים של קוד פתוח. זה לא יתן משכורת אבל יתן לך נסיון שאת זקוקה לו.
התנדבות זה בדיוק הדרך לעבודות עם שעות יותר גמישותמשה
את חייבת להראות שאת שווה משהו יותר מאחרים וששווה להתגמש בשבילך. את הנסיון הזה את לא תוכלי לצבור בעבודה שאת לא מקבלת.
פרוייקט קוד פתוח כן יתן לך את זה.
מצד שני, אני חכם גדול. אני עשיתי את הפרוייקטים בחינם שלי בגיל 14....
איפה מעסיקים ילדים בני 14 בתכנות?מתיישב בנשמה
גם בהתנדבות....
אף אחד לא יעסיק אותך, אבל אם תיזום פרוייקט תהיה לך עבודהמשה
אני פשוט יזמתי בזמנו את הפורומים של "עזרא" שסיפקו לי ים של תעסוקה לשנות העשרה.
עבודה מול מעצבי וורדפרס/WIXמושיקו
עבודה מול חו"ל.
כל מיני עבודות שטותיות של העברות וסידור נתונים.
לחשוב בראש גדול מה הסביבה הקרובה צריכה ולהציע לה את זה
חשבת על משרות סטודנט?עוקר הרים
אפשר לקבל שכר סביר (60-80 לשעה) ושעות נוחות.
מה ההכשרה שלך?
לאו דווקאעוקר הרים
אם לא אכפת לך לקבל תנאים של סטודנט אז חלק מהמקומות יסכימו.
אפשר גם לחשוב בכיוון של פרילנסעוקר הרים
פרילנס זה רעיון מצויין אבל צריך לפחות 4 שנות נסיון לזהמשה
זה לא כמו ארגון גדול שאם תפספס משהו יגבו אותך.
תלוי מה אופי הפרוייקטעוקר הרים
פרויקטים פשוטים/ תגבור צוות פיתוח וכדו' לא חייבים הרבה נסיון.
"לתגבר" רוצים מישהו שיודע את העבודה, לא מתלמדמשה
אחרי 5-6 שנים כשכיר זה אפשרי. לא קודם.
לא כל כך הרבה ולא בכל תחוםעוקר הרים
ברוב המקומות 3 שנות נסיון נחשב מספיק בהחלט. רק במיעוט יבקשו 5 ומעלה. (אני מתגבר צוות פיתוח. התחלתי עם 3 שנות נסיון. אני חושב שהם בהחלט לא התחרטו...☻).
בחלק מהמקומות, אם מוכיחים ידע רלוונטי אפשר להתקבל (בשכר נמוך) גם עם נסיון מועט.
ההיגיון בזה פשוט. הסיכון בפרילנס לא טוב הוא נמוך בהרבה מעובד לא טוב והעלות נמוכה בהרבה.
אם יש נסיון רלוונטי זה קל יותר. הבעיה היא שעוד אין לה.משהאחרונה
מכיר לא מעט חברות שלא מעניינות אותן השעות אלא רק מספר השעותספק
מוזר שאת כותבת את זה.
אני מכיר בית תכנה בבני ברק שמעסיק בעיקר נשים חרדיות.
ממה שהבנתי, התנאים שם הם לא הכי טובים בשוק, אבל מטבע הדברים, השעות שם נוחות.
בתי תכנה חרדים זה (לרוב) פחות ממשרת סטודנטעוקר הרים
עניינים של ביקוש,היצע ויכולת מיקוח.
מבחינת התנאיםעוקר הרים
מבחינת רצינות הפרויקטים - יש ויש, אבל בהחלט יש חברות רציניות מאוד.
גם משרות סטודנט יש רציניות מאוד.
מסכים בהחלט.עוקר הרים
יש לך יתרונות על פני האחרים ללא הניסיון?אליסף א
צורת חשיבה מקורית.
הכירות עם תחומי ידע נוספים (פיזיקה? אלקטרוניקה?)
את יודעת לכתוב אנדרואיד?
אם ענית על אחד מאלה
אולי יהיה על מה לדבר אצלנו.
אני צריך לשאול את הבוס.
תחפשי בחברות גדולותריבוזום
שם לרוב די רגוע, שלא כמו בסטרטאפים.
אצלינו למשל ממש אין בעיה לעבוד מ 7:00 עד 15:30. אפשר גם לעבוד מהבית במקרה הצורך (אני מכירה מישהי שעושה את זה באופן קבוע יומיים בשבוע. מן הסתם בהתחלה צריך להיות במשרד רוב הזמן כי חייבים תקשורת ועזרה, אבל תמיד אפשר להשלים כמה שעות מהבית).
מישהו יודע איפה אפשר ללמוד איך לבנות אתר?חיים987
האם אפשר לבנות אתר בוויזואל סטודיו 2017?
כןעוקר הרים
באיזו טכנולוגיה אתה רוצה לבנות את האתר?
באיזה טכנולוגיה אפשר?חיים987
האם אפשר שהאתר לא יהיה גלוי לכלחיים987
מה הכוונה?עוקר הרים
למי אתה רוצה שיהיה גלוי ולמי לא.
הרבה מאודעוקר הרים
כברירת מחדל מותקנים asp.net, mvc.net ו-node.js.
אפשר להתקין עוד.
אגב, visual studio הוא IDE מאוד כבד. להרבה מאוד טכנולוגיות יש IDE יותר פשוט.
מה זה node.js?מתיישב בנשמה
צד שרת שכתוב ב-javascriptעוקר הרים
ליתר דיוק - סביבת הרצה לקוד javascript, מבוססת אירועים שמתאימה בעיקר לאפליקציות IO.
אם מעניין אותך יותר -
Express - Node.js web application framework
כדאי גם
https://git-scm.com/
Visual Studio Code - Code Editing. Redefined
אם מעניין אותך הסברים מפורטים יותר - אני יכול להרחיב
אם תוכל להרחיב...חיים987
איך עובדים עם האתרים האלהחיים987
יש איזה מדריך שמסביר איך לעבוד עם Visual Studio Codeחיים987
אני יכול להסבירעוקר הרים
אבל אם אתה מתחיל ב-web וקשה לך ללמוד מהאינטרנט. node.js זה לא הכלי שהייתי מתחיל בו.
אבל אם אתה רוצה - תוריד ותתקין visual studio code ו-node.js.
צור תיקיה ופתח אותה ב-vscode.
פתח את שורת הפקודה במיקום של התיקיה (קיצור מקשים `+ctrl).
כתוב npm init. הוא ייצור איתך קובץ packages.json שזה הקובץ שמגדיר את הפרויקט שלך.
תעבוד על פי המדריך הזה - Node.js Express Framework
במקום להריץ באמצעות node server.js, תריץ עם F5 כשאתה בקובץ server.js.
כשאתה מסיים/ מסתבך תחזור לפה לדווח...
פתח את שורת הפקודה במיקום של התיקיה (קיצור מקשים `+ctrl).חיים987
מה הכוונה
זה צילום מסךחיים987
כשהתכנה פתוחה ;+ctrlעוקר הרים
(המקש שמשמאל למספרים - מעל לטאב).
כשרשמתי את הnpm היה רשום לי רק שנפתח package ובאתר הם רושמיםחיים987
כל מיני דברים שלא היה רשום לי
זה הצילום מסך
זה הpackage
מה הלאהחיים987
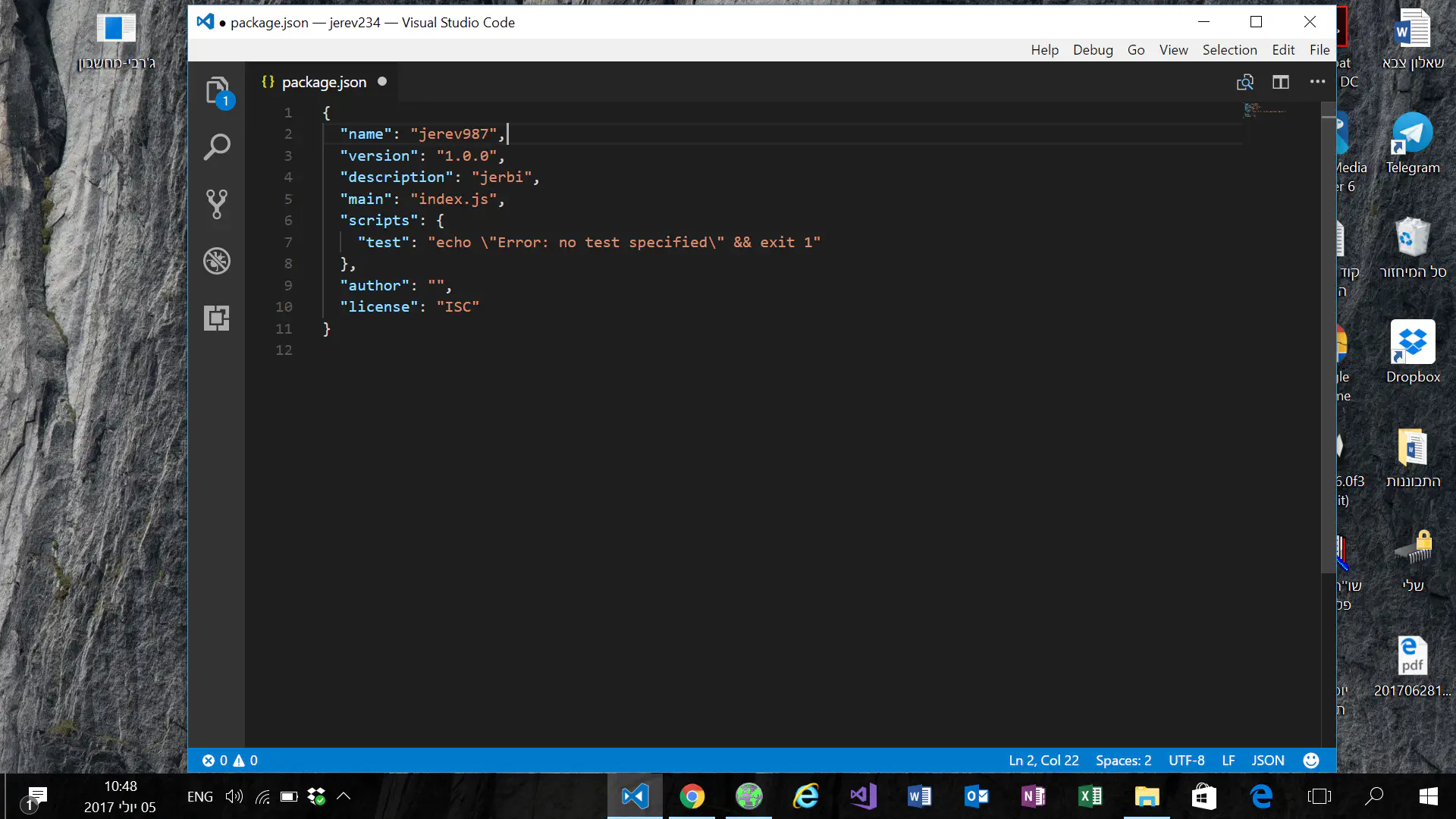
להמשיך על פי המדריךעוקר הרים
(לכתוב בשורת הפקודה
npm install express --save
וכו')
התקדמתי, כשהגעתי ל-node server.jsחיים987
ורשמתי את ההוראה הנ"ל, על מנת להכניס בתוכה את הפקודות
התוצאה שקיבלתי זה ERORחיים987
זה הצילום מסך, מדוע קיבלתי EROR
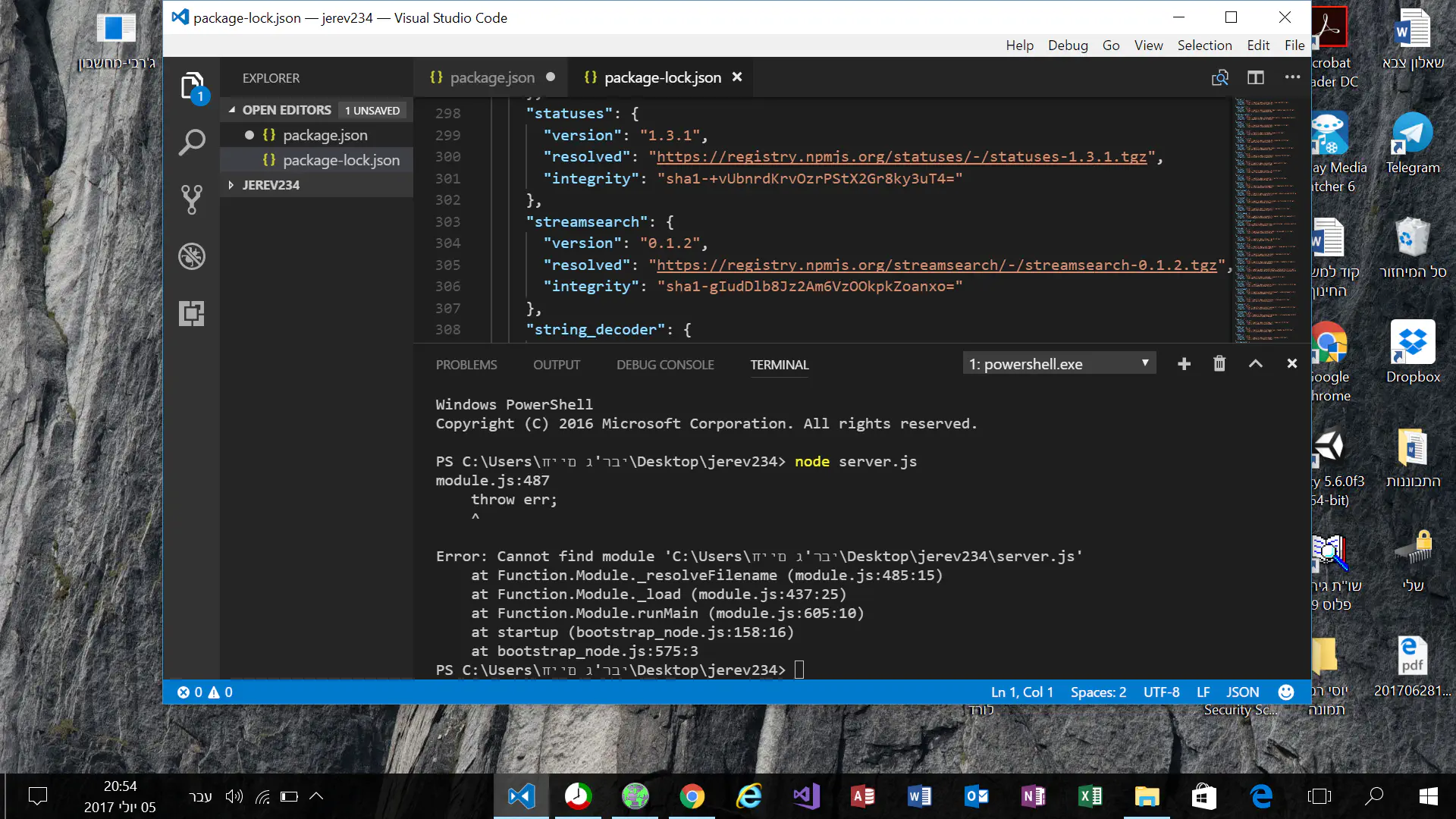
לא יצרת את הקובץ server.jsעוקר הרים
לא מופיעה איך יוצריםחיים987
א -גוגלעוקר הרים
ב- בסרגל הכלים השמאלי - תרחף עם העכבר מעל הפאנל התחתון (עם שם התיקיה בכותרת). תראה 4 אייקונים בכותרת של הפאנל, רחף מעליהם ותראה ישועות!
לא הבנתי איפה בצד שמאלחיים987
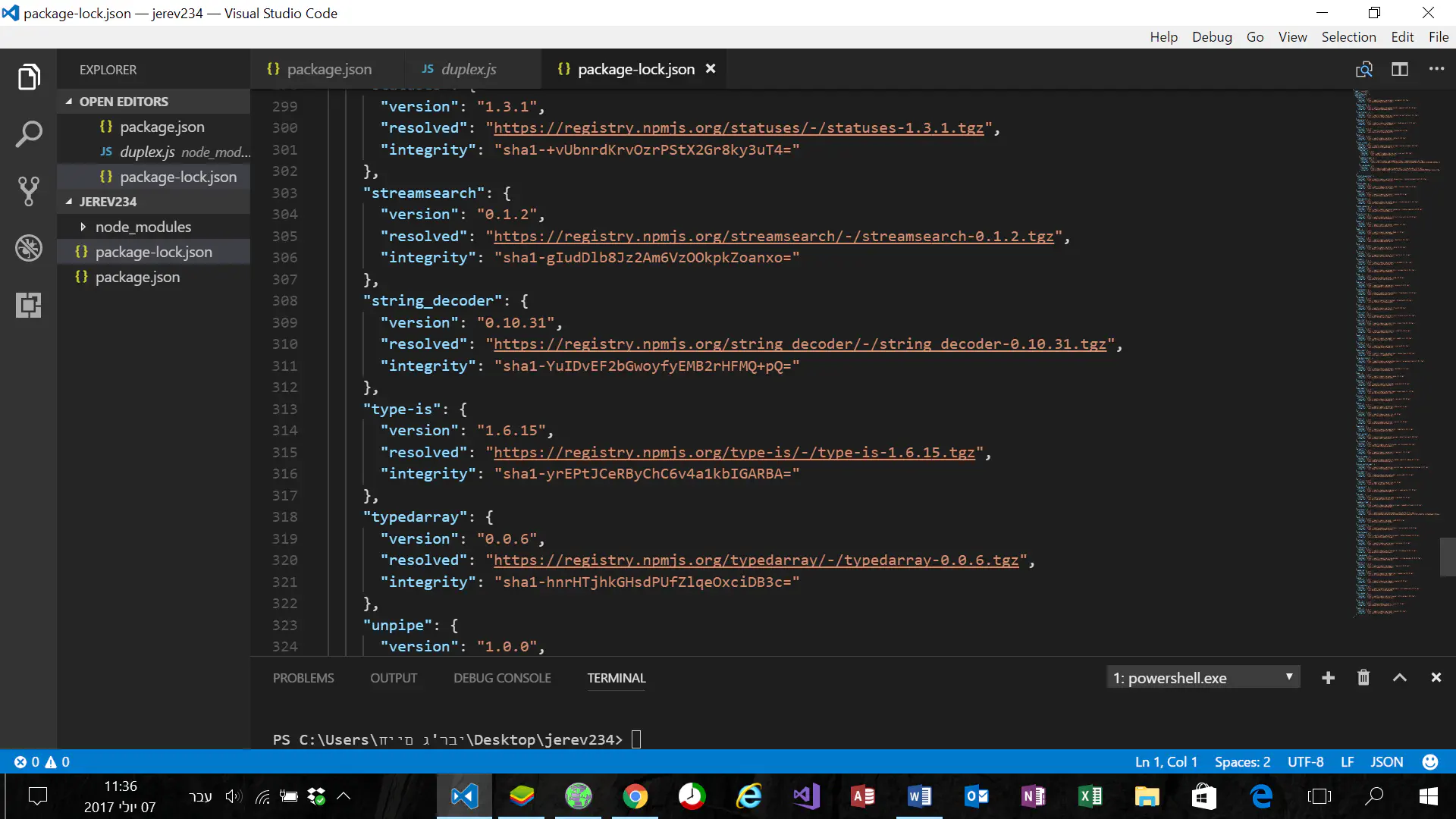
איפה שהקבציםעוקר הרים
וגוגל
אתה יכול לבנות אתר ב Visual Studio 2017 enterprise.אנונימיתית
אני בניתי אתר בתוכנה הנ"ל במסגרת התואר אך לא הייתי צריכה לעלות אותו לענן.
יש לי פרופסיונל - גם שם אפשר?חיים987
בכל הגרסאותעוקר הרים
יש לי את זה, איך בונים שם אתר?, זה יותר פשוט?חיים987אחרונה
ערימת מינימוםהשמח בחלקו
מישהו יכול להסביר איך זה עובד בצורת מערך?
ומה בכלל העקרונות שלה?
ויקיפדיה יכולהמייק ווזאבסקיאחרונה
תואר במדמ חממשה
האם שווה לעשות תואר ראשון במדעי המחשב אם רוב הסיכויים שהממוצע של הציונים יהיו נמוכים באזור השבעים האם שווה את ההשקעה לאחד שהוא כבר באמצע שנה ראשונה??
תודהרבה
זה כזה פשוט ?ממשה
אם עכשיו שבעים אז אני לוקח צד גדול שככה זה ימשיך וברור שאנסה לעלות
כולם שואלים מה הממוצע ??ומה בקשר למשרות לא בפיתוח ממש ??
תודה
בעיהמתיישב בנשמה
כתבתי בphp את הקוד הבא:
$passwd= $_POST['passwd']; $spasswd=md5($passwd); $username= mysql_real_escape_string($_POST['username']); $link = mysql_connect("localhost", "root", ""); if (!$link) { die("Could not connect: " . mysql_error()); } $db_selected = mysql_select_db("contacts", $link); if (!$db_selected) { die ("Can't use internet_database : " . mysql_error()); } $tpasswd = mysql_query("SELECT password FROM contacts WHERE username LIKE '$username'"); if(!$tpasswd){ print "you entered wrong username."; } elseif($spasswd==$tpasswd){ print "hello $username"; setcookie('login?','yes'); setcookie('username',$username); } else{ print "wrong password"; }
וכשאני מריץ את זה בדפדפן ומכניס את הסיסמא הנכונה (passwd$ ) הוא עושה את הפעולה של הelse, למה הוא עושה את זה? מה הטעות?
יש לך אפשרות לרוץ עם debugger שורה אחרי שורה?משה
זה מסוג הדברים שהדרך לאתר אותם זה לרוץ step by step ולעקוב אחרי כל משתנה. הכי קל במקום להתחיל לנחש.
אתה משתמש בכלי כמו eclipse? או N++ ועורכי טקסט?
אגב זה גם קוד לא מאובטח (מבחינת העוגיה), אבל זה מספיק לך כרגע.
אני משתמש בwebmatrix, אין שם step by step...מתיישב בנשמה
אז איך אני הופך אותו למאובטח?
נראה לי שהבעיה שלך היא ב-mysql_query...מייק ווזאבסקי
הוא מחזיר אובייקט שעליו צריך לבצע את הפונקציה: mysql_fetch_assoc
תראה איך משתמשיםב זה כאן: PHP: mysql_fetch_assoc - Manual
בכל מקרה, כדאי להוסיף LIMIT 1 לשאילתה...
איך שכחתי|דופק ת'ראש בקיר|מתיישב בנשמה
ה username הוא ממילא מפתח ראשי, כך שאין סיכוי שיהיו 2.מתיישב בנשמה
אז רק בשביל היעילות...מייק ווזאבסקיאחרונה
כי אין טעם להמשיך לחפש אחרי שמצאת אחד...
איך עושים עברית בDB שלmysql?מתיישב בנשמה
מדריך...מייק ווזאבסקיאחרונה

בטוחה שזה המקום של הקובץ?איזה_טוב_ה'_
דרך איפה העלית?
כבר ניסיתי כל מיני אפשרויות אז מחקתי...עלה למעלה
העלתי לשרת..
קיצור לא יודעת הסתבכתי לגמרי:-/
קיצור לא יודעת הסתבכתי לגמרי:-/
עכשיו העלתי את זה לפהעלה למעלה
יש שגיאה ב-javascriptעוקר הרים
קטע הקוד הבא מחזיר undefined, אולי זה קשור?
queue.getResult(ssMetadata[i].name)
והוא לא מוצא את הקובץ הבא -
http://www.siur123.co.il/siur4/yarden/shamor/wp-content/vidio/images/באנר שילוח_atlas_.png
מה זה אומר?עלה למעלה
מה אפשר לעשות כדי לתקן את זה?
לא יודע אם קשוראיזה_טוב_ה'_
אבל תנסי להעלות עם שם באנגלית ובלי רווחים
ניסיתי לא הלך...עלה למעלה
מה שם הקובץ שאת מעלה?עוקר הריםאחרונה
איך אני אומר לPHP לנעביר אותי לדף אחר?מתיישב בנשמה
אתה מתכווןעוקר הרים
לא משנה, הסתדרתימתיישב בנשמהאחרונה
בתור מתחיל שמאוד מתעניין באיזה אתרים הייתם ממליצים לי ללמודחיים987
על איך עובד האינטרנט?
לימוד HTML ןPHP ועוד
בקיצור על כל התחום הזה למתחילים
כמה מקומותעוקר הרים
W3Schools Online Web Tutorials
וובמאסטר - תיכנות ובניית אתרים
המדריכים ב-webmaster לא ברמה אחידה, חלקם די מיושנים. אבל הם בעברית.
וכמובן - גוגלעוקר הרים
כל דבר ספציפי שאתה מנסה לעשות ולא מצליח - Google it.
הייתי ממליצה ללמודעלה למעלה
Php
Html
Css
וורדפרס
Html
Css
וורדפרס
מה זה וורדפרסחיים987
מערכת של קוד פתוח לבניית אתריםעלה למעלה
לא מסובך לבנות את זה
תלוי איזה סוג של אתרים הוא רוצהעוקר הרים
אם הוא רוצה להיות לא רק בונה אתרים, אלא מתכנת, php ווורדפרס זה לא כיוון טוב.
למה לא?עלה למעלה
בגלל זהעוקר הריםאחרונה
Toggl - Free Time Tracking Software
וברצינות, php היא שפה לבניית אתרים, אבל פשוט לא שפת תכנות טובה.
השפות העיקריות שנחשבות היום בתכנות צד שרת הן (למיטב ידיעתי) - javascript, java, C#, python, ruby.
מה זה blob בjs ואיך אני מגיע אליו?baruchiro
יש לי דף אינטרנט (לא אני כתבתי) שמציג ב<video> עם מקור blob:http://www.blablalba.co.il
מה זה הblob הזה? (הבנתי שזה איזה cache)
איפה הקובץ קיים?
איך אני מגיע אליו?
הסברעוקר הריםאחרונה
https://developer.mozilla.org/en-US/docs/Web/API/Blob
javascript - Convert blob URL to normal URL - Stack Overflow
זה קובץ שנוצר בקוד ה-javscript. (ייתכן שאם תבדוק ב-network של הדפדפן תגלה שהוא בעצם הגיע מהשרת).
הקובץ קיים בזיכרון של הדפדפן.
זו דרך נוחה ליצור קובץ באמצעות קוד ולהציג אותו למשתמש, בעיקר לשם הורדה או פתיחה בעמוד אחר.
בקישור ל-stack overflow יש דוגמת קוד איך לחלץ את הקובץ בעזרת ה-blob.